AC 自动机
单模式串匹配算法
在实际生活中我们有用到在特定字符串中查找子串的需求,接下来为了更好地讲解,我们给出下面两个名词解释:
- 主串:一个待查找模式串是否包含在内的字符串
- 模式串:表示在主串中查找的模式字符串
例如,我们希望在字符串 AABBAACACB 中匹配 ACA 字符串,那么前者表示的是主串,后者就是模式串。那我们应该如何进行查找这个字符串是否包含在内,也有很多方法,我们先讲一个最朴素的做法,暴力匹配。
暴力匹配
以字符串 AABBAACACB 中匹配 ACA 字符串为例,我们遍历字符串 的下标并每次截取 个长度的字符串逐个比较,直到判断到存在 满足 说明我们在 匹配到了 。
我们来分析一下时间复杂度,设 分别表示字符串 的长度,对于遍历每一个 的下标都要反复截取 个字符串作为比较对象;并且在比较长度相同均为 的字符串 是否一致,需要遍历 次去查看每个字符是否一致,所以复杂度是 。
下面是代码参考:
bool brute_force_match(string main_string, string pattern_string)
{
int main_string_length = main_string.size();
int pattern_string_length = pattern_string.size();
for (int i = 0; i <= main_string_length - pattern_string_length; i++)
{
int j;
for (j = 0; j < pattern_string_length; j++)
{
if (main_string[i + j] != pattern_string[j])
{
break;
}
}
if (j == pattern_string_length)
{
return true;
}
}
return false;
}失配跳转法
既然我们已经知道了模式串已经匹配掉了一些信息,我们就优先考虑选取已经重复的部分进行失配跳转,我们先从一个简单的例子讲起,例如 ABABABC 与 ABABC,首先我们做一个预处理,如果我们从 遍历到 发现该字符与模式串失配,那么我们就考虑从 开始遍历而不是从 继续遍历,即跳过开头的 AB 从下一个 AB 开始匹配。下面是一个图例:
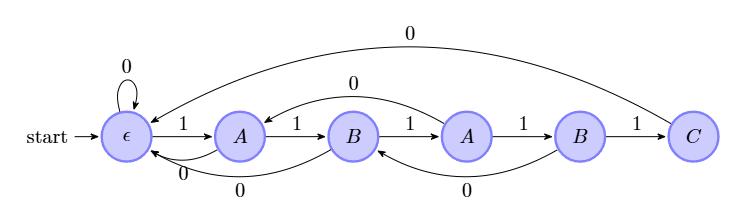
首先我们不去追究这个自动机是怎么跳转的,我们拿到这样一个自动机的示意图,首先我们拿模式串 =ABABC 进行匹配:
- 进行第一次匹配:我们发现在 C 的位置失配了,对应字符串的 ,此时 (也是匹配的长度), 那么此时下标之差 ,所以我们选择继续跳过 位再匹配。
- 进行第二次匹配:发现完全匹配,直接返回
true即可。
时间复杂度是 ,接下来来介绍如何构建这样的失配指针自动机图,主要是记住如下三个点即可:
构建 kmp 自动机
- 首先构建一个虚拟节点 ,然后建立一个字符串链表。
- 令指针 的初值为上一个节点 的 fail 指针。若 所指向节点的下一个节点与 不匹配,则不断令 跳转至其自身的 fail 指针,直到找到一个节点,其下一个节点恰好等于 ,或者 已退无可退回到 。若最终匹配成功,则构建 指向该匹配节点的下一个节点;若始终无法匹配,则 。 的
fail指针还是指向 。 - 在匹配过程中在 上失配,就将字符串向右偏移 个单位。
接下来请同学们练练手,尝试自己绘制一个 ABAABAACAACA kmp 自动机图。
答案
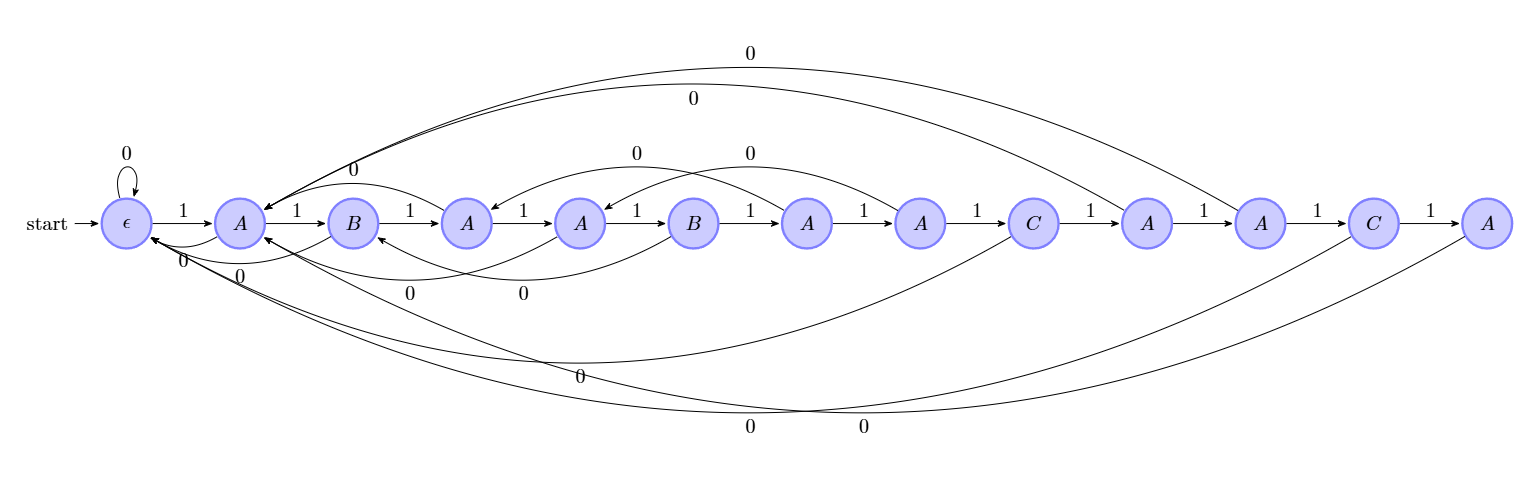
接下来我们尝试 ABAABAABAACAACA 中匹配 ABAABAACAACA。首先:
A B A A B A A B A A C A A C A
A B A A B A A C A A C A
^此时 ,,
A B A A B A A B A A C A A C A
A B A A B A A C A A C A下面是代码过程:
bool kmp_automata(string main_string, string pattern)
{
int n = (int)main_string.size();
int m = (int)pattern.size();
if (m == 0)
return true; // 空模式认为匹配
if (n < m)
return false;
// 构造 pi 数组:pi[i] = pattern[0..i] 的最长真前缀-后缀长度
vector<int> pi(m, 0);
for (int i = 1; i < m; ++i)
{
int j = pi[i - 1];
while (j > 0 && pattern[i] != pattern[j])
j = pi[j - 1];
if (pattern[i] == pattern[j])
++j;
pi[i] = j;
}
int i = 0; // 当前在主串上尝试的“窗口起点”
while (i <= n - m)
{
// 直接暴力比较从 i 开始与模式的每一位(这样能获得第一次失配时的 j)
int j = 0;
while (j < m && main_string[i + j] == pattern[j])
++j;
if (j == m)
return true; // 完全匹配
// 在模式 j 位置失配(如果 j==0 表示第一个字符就失配)
int fail = (j == 0 ? 0 : pi[j - 1]); // fail 指针语义
int delta = j - fail; // 按你说的 delta
if (delta <= 0)
delta = 1; // 保险措施(理论上 delta>0)
i += delta;
}
return false;
}最长公共真前后缀长度
如果你仔细看的话,其实 就是当前 的最长公共真前后缀长度 意味着:模式串的前 个字符与当前失配位置前 个字符完全相同,直观理解是假设我们匹配到某个位置失败了:
- 已匹配的字符串:
ABCAB - 最长公共真前后缀:
AB(即前缀AB等于后缀AB)
这意味着:
- 你刚才在文本串里匹配到的那部分后缀是
AB。 - 既然
AB等于模式串的开头,那么你不需要把模式串移回开头,只需要把模式串的“前缀”滑过去对齐刚才的“后缀”即可。
接下来我们对 抽象成一个数组 表示前 个字符的字符串最长公共真前后缀长度,除了之前使用模拟的方法记忆化搜索 ,这里介绍一种动态规划的做法:
设字符串为 首先如果 那么我们可以得到 ,直观表现是如果前 个字符的最长公共真前后缀长度 所对应的第 个字符 的话,那说明前 个字符的最长公共真前后缀就是 ,可以阅读下面的图片辅助理解: